Обработка информации
Давайте разберёмся, как устроена цифровая вселенная вокруг нас. Представь: каждый раз, когда ты отправляешь мем другу, стримишь на Twitch или просто гуглишь что-то для реферата — происходит обработка информации. Это не просто техническая магия, а строгая логика, которую можно понять и использовать. Готов нырнуть глубже?

Обработка информации — это превращение хаоса данных в упорядоченные структуры, понятные человеку и машине
Что такое обработка информации?
Информационный процесс — это последовательность действий над информацией (данными, фактами, идеями) для достижения какой-то цели. Можно выделить три основных типа: обработка, хранение и передача.
💡 Определение
Обработка информации — целенаправленный процесс изменения содержания или формы представления информации.
🤔 Интересный парадокс
Мы часто думаем, что обработка — это всегда создание чего-то нового. Но на самом деле существует два фундаментально разных типа обработки. Как ты думаешь, какие?
Два типа обработки информации
При всём многообразии решаемых задач обработка информации делится на два принципиально разных типа.
🔬 Тип 1: Создание нового содержания
Этот тип обработки создаёт новую информацию, новое знание:
- Вычисления по формулам — расчёт траектории в игровом движке
- Исследование объектов через модели — симуляция погоды, прогноз трендов в соцсетях
- Логические рассуждения и обобщения — как алгоритм рекомендаций YouTube "понимает", что тебе показать дальше
🔄 Тип 2: Изменение только формы
Этот тип обработки не меняет смысл, только представление:
- Кодирование — переход к другой форме (текст → двоичный код → пиксели на экране)
- Структурирование — организация информации по правилу (playlist в Spotify, папки с файлами)
- Поиск и отбор — нахождение нужного в массиве данных (поиск в Google Drive, фильтры в интернет-магазинах)
❓ Вопрос для размышления
Когда компрессор сжимает видео для загрузки в TikTok — это какой тип обработки? А когда нейросеть генерирует новое изображение по твоему промпту?
Общая схема обработки информации
При любой обработке информации всегда решается некоторая информационная задача.
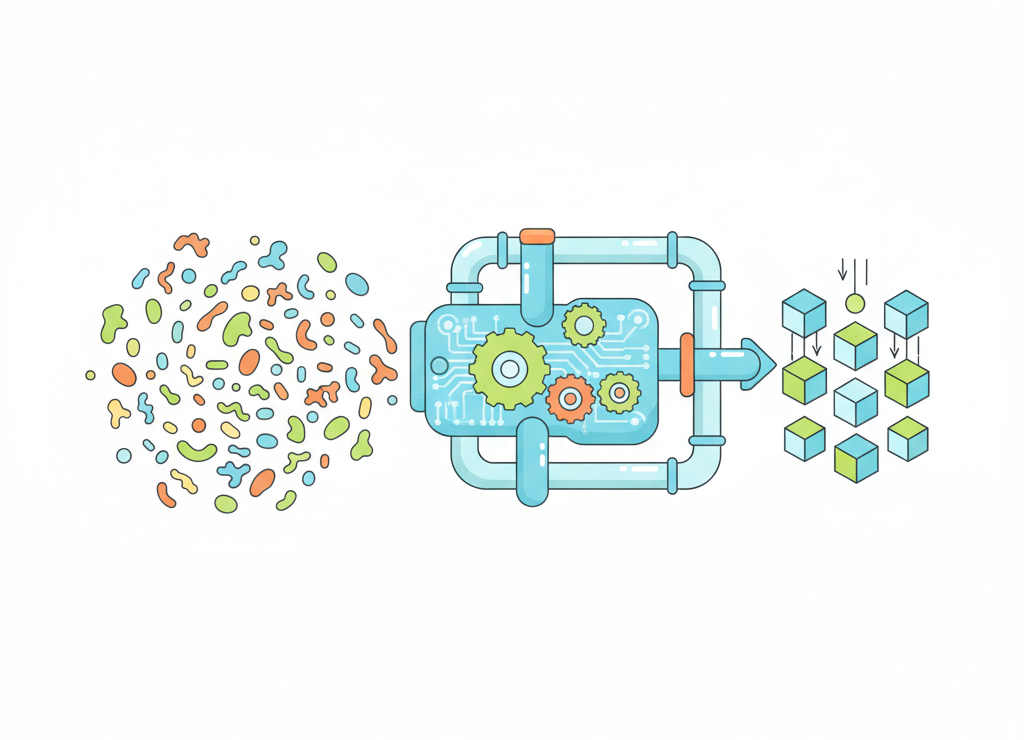
Любая обработка информации проходит через три этапа: входные данные → алгоритм обработки → результат
🎯 Элементы процесса обработки
Дан некоторый набор исходных данных — исходной информации, требуется получить некоторые результаты — итоговую информацию. Сам процесс перехода от исходных данных к результату и есть процесс обработки.
- Исполнитель обработки — объект, который осуществляет обработку (человек или компьютер)
- Алгоритм обработки — последовательность действий, которую нужно выполнить для достижения результата
👤 Человек как исполнитель
Неформальный, творчески действующий исполнитель. Даже для решения самой простой математической задачи разные люди могут использовать разные способы!
💻 Компьютер как исполнитель
Формальный исполнитель. Его действия осуществляются автоматически, строго в соответствии с имеющимся алгоритмом обработки информации.
4.1. Кодирование информации
Ты когда-нибудь задумывался, почему твоё сообщение в мессенджере, отправленное с телефона, читается на компьютере друга? Или как Netflix передаёт видео так, чтобы оно не занимало весь интернет-канал? Всё дело в кодировании.
📝 Основные понятия
- Кодирование — это преобразование информации в форму, удобную для хранения, передачи или последующей обработки
- Код — система условных обозначений (кодовых слов), используемых для представления информации
- Кодовая таблица — совокупность кодовых слов и их значений
Примеры кодов
⚖️ Равномерные коды
Каждый символ кодируется одинаковым числом бит:
- Код Бодо — 5 бит на символ
- ASCII — 8 бит на символ
Преимущества: простота, надёжность. Такие коды используются повсеместно в современных компьютерах.
📡 Неравномерные коды
Разные символы кодируются разным числом бит:
- Азбука Морзе — частые буквы короче, редкие длиннее
- Алгоритмы сжатия — используют неравномерное кодирование для уменьшения размера файлов
Преимущества: эффективность для частых символов.
Азбука Морзе — классический неравномерный код
Самый известный пример неравномерного кода, названный в честь Сэмюэля Морзе (1791–1872). Буквы, встречающиеся в сообщениях чаще, имеют более короткий код.
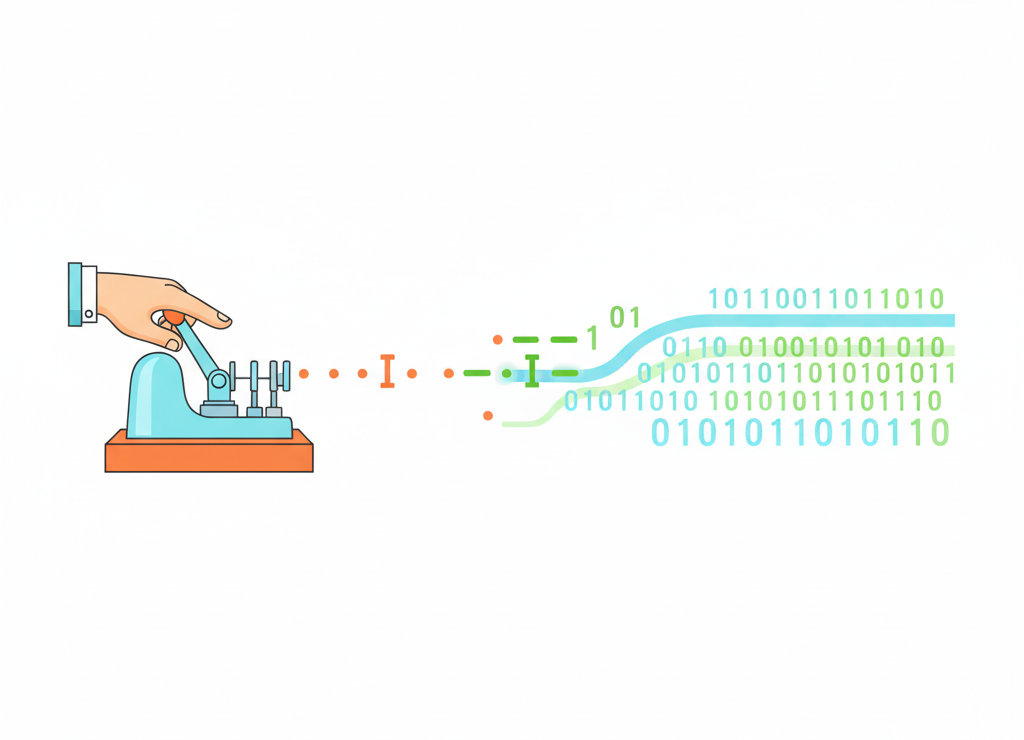
От точек и тире азбуки Морзе до двоичного кода компьютеров — эволюция систем кодирования информации
⏱️ Временные параметры азбуки Морзе
За единицу измерения длительности сигналов принимается длительность сигнала "точка":
- Тире = 3 точки
- Пауза между сигналами одного знака = 1 точка
- Пауза между знаками в слове = 3 точки
- Пауза между словами = 7 точек
Важно: Фактически пауза является третьим знаком в азбуке Морзе, а сам код — троичным!
🆘 Самое знаменитое сообщение
Сигнал бедствия SOS (•••———•••) передаётся без межбуквенных пауз. Его запрещено использовать без острой необходимости.
Комбинаторика кодов
При использовании неравномерных кодов важно понимать, сколько различных кодовых слов они позволяют построить.
📊 Правило умножения
Если элемент A можно выбрать n способами и при любом выборе A элемент B можно выбрать m способами, то пару (A, B) можно выбрать n · m способами. Это правило справедливо для произвольного количества независимо выбираемых элементов.
✏️ Пример 1: Светодиодная панель
Задача: Светодиодная панель содержит восемь излучающих элементов, каждый из которых может светиться красным, жёлтым, синим или зелёным цветом. Сколько различных сигналов можно передать?
Решение:
4 варианта для первого элемента × 4 для второго × ... × 4 для восьмого = 4⁸ = 65 536 различных сигналов
Это как если бы у тебя был алфавит из 4 символов, и ты составляешь из него все возможные 8-символьные "слова". Количество комбинаций растёт экспоненциально!
✏️ Пример 2: Последовательности точек и тире
Задача: Сколько символов можно закодировать последовательностями точек и тире длиной не более 6 знаков?
Решение:
- Длиной 1: 2 варианта
- Длиной 2: 2² = 4
- Длиной 3: 2³ = 8
- Длиной 4: 2⁴ = 16
- Длиной 5: 2⁵ = 32
- Длиной 6: 2⁶ = 64
Всего: 2 + 4 + 8 + 16 + 32 + 64 = 126 различных символов
✏️ Пример 3: Сочетания с комбинаторикой
Задача: Четырёхбуквенный алфавит {A, B, C, D}. Сколько существует 7-символьных последовательностей, содержащих ровно 5 букв А?
Решение:
Нужно:
- Выбрать 5 мест из 7 для буквы А
- На оставшихся 2 местах разместить любые из B, C, D
Число способов выбрать 5 мест из 7 вычисляется как число сочетаний:
C₇⁵ = 7!/(5!·2!) = (7·6)/(1·2) = 21На каждых 2 оставшихся местах может быть любая из 3 букв: 3 × 3 = 9 вариантов.
Итого: 21 × 9 = 189 различных последовательностей
Префиксные коды и условие Фано
В технических системах критически важно, чтобы закодированное сообщение можно было однозначно декодировать. Для этого используются префиксные коды.
💡 Определение
Префиксный код — код со словом переменной длины, обладающий тем свойством, что никакое его кодовое слово не может быть началом другого (более длинного) кодового слова.
✅ Примеры префиксных кодов
- Код {0, 10, 11} — префиксный
- Код {00, 01, 10, 11} — префиксный
❌ Примеры НЕ префиксных кодов
- Код {0, 10, 11, 100} — 0 является началом 00
- Код {1, 10, 101} — 1 является началом 10 и 101
📏 Условие Фано
Названо в честь Роберта Марио Фано, американского учёного, известного по работам в области теории информации.
- Прямое условие Фано: никакое кодовое слово не является началом другого (более длинного) слова
- Обратное условие Фано: никакое кодовое слово не является окончанием другого (более длинного) слова
Для однозначного декодирования достаточно выполнения одного из условий Фано — или прямого, или обратного.
🔄 Правила декодирования
- Если выполняется прямое условие Фано → декодируем слева направо
- Если выполняется обратное условие Фано → декодируем справа налево
Пример декодирования
Рассмотрим задачу декодирования двоичной строки с использованием условия Фано.
✏️ Пример 4: Декодирование строки
Задача: Даны коды для 5 букв латинского алфавита:
| A | B | C | D | E |
|---|---|---|---|---|
| 000 | 01 | 100 | 10 | 011 |
Декодировать строку: 0110100011000
Анализ кодов:
- B (01) — начало E (011) ❌
- D (10) — начало C (100) ❌
Вывод: Прямое условие Фано НЕ выполняется.
Проверка обратного условия: никакой код не является окончанием другого ✓
Вывод: Обратное условие Фано выполняется! Декодируем справа налево.
Процесс декодирования (справа налево):
0110100011000
↓
0110100011A
↓
0110100EA
↓
0110CEA
↓
01DCEA
↓
BDCEAОтвет: BDCEA
Кодовые деревья
Префиксные коды удобно представлять с помощью бинарных деревьев — иерархической структуры, состоящей из набора вершин и рёбер.

Бинарное дерево префиксного кода: каждый лист представляет уникальное кодовое слово, путь к которому не может быть началом пути к другому листу
🌳 Основные понятия
- Корень — вершина, в которую не входит ни одного ребра
- Листья — вершины, из которых не выходит ни одного ребра
- Двоичное (бинарное) дерево — дерево, из вершин которого выходит только два ребра
Важно: Комбинации, соответствующие листьям бинарного дерева, являются кодовыми комбинациями префиксного кода.
✏️ Пример 5: Построение кодового дерева
Задача: Для кодирования последовательности из букв А, Б, В и Г используется неравномерный двоичный код: А = 0, Б = 10, В = 110. Каким кодовым словом может быть закодирована буква Г?
Решение:
Строим бинарное дерево и отмечаем занятые вершины (листья) для А, Б и В. Так как комбинациям префиксного кода должны соответствовать листья дерева, свободные листья — возможные коды для Г.
Кратчайшее кодовое слово для Г: 111
4.2. Поиск информации
Сколько раз в день ты что-то ищешь? Контакт в телефоне, файл на диске, мем в галерее, нужный трек в плейлисте? Поиск — это одна из ключевых операций обработки информации.
🎯 Задача поиска
Имеется некоторое хранилище информации — информационный массив (телефонный справочник, словарь, расписание поездов, диск с файлами). Требуется найти в нём нужную информацию, удовлетворяющую определённым условиям поиска.
При этом необходимо сократить время поиска, которое зависит от двух факторов:
- Способ организации набора данных
- Используемый алгоритм поиска
💭 Вопрос для размышления
Вспомни, как часто и какую информацию приходится искать тебе, членам твоей семьи, твоим друзьям и знакомым. Приведи примеры из своей цифровой жизни.
Метод последовательного перебора
Если данные никак не организованы (неструктурированный набор), остаётся только метод последовательного перебора.
🔍 Как работает метод
Все элементы, начиная с первого, просматриваются подряд. Поиск завершается в двух случаях:
- Искомый элемент найден — может быть просмотрена как часть набора данных, так и весь набор (если искомый элемент последний)
- Просмотрены все элементы — искомого элемента среди них не оказалось
⏱️ Длительность поиска
Средняя длительность: N/2, где N — размер набора данных
- Лучший случай: искомый элемент первый → 1 просмотр
- Худший случай: искомый элемент последний или его нет → N просмотров
- В среднем: N/2 просмотров
Пример из жизни: Представь, что ищешь нужный трек в плейлисте из 1000 песен, который не отсортирован. В среднем придётся прослушать названия примерно 500 треков. Долго, правда?
Метод половинного деления (бинарный поиск)
Если данные структурированы (упорядочены по неубыванию), можно использовать гораздо более эффективный алгоритм.

Бинарный поиск: каждый шаг отсекает половину вариантов, делая поиск экспоненциально быстрее последовательного перебора
🎯 Условие применения
Элементы набора данных упорядочены по неубыванию, то есть каждый последующий элемент не меньше (больше или равен) предыдущего:
a₁ ≤ a₂ ≤ a₃ ≤ ... ≤ aₙ🔄 Алгоритм работы
- Находим центральный элемент: номер [N/2] + 1
- Сравниваем искомый элемент с центральным
- Если искомый > центрального → ищем в правой половине
- Если искомый < центрального → ищем в левой половине
- Если совпали → поиск завершён
- Повторяем процесс для выбранной половины
Пример работы бинарного поиска
Рассмотрим подробный процесс поиска методом половинного деления.
✏️ Пример 6: Поиск числа 180
Дана последовательность чисел:
061 087 154 180 208 230 290 345 367 389 456 478 523 567 590 612Просмотр 1: Работаем со всей последовательностью
061 087 154 180 208 230 290 345 367 389 456 478 523 567 590 612
↑
Центральный элементСравниваем: 180 < 367 → отбрасываем правую часть
Просмотр 2: Работаем с левой частью
061 087 154 180 208 230 290 345
↑
Центральный элементЦентральный элемент совпадает с искомым!
Результат: Поиск завершён за 2 шага (при последовательном переборе потребовалось бы 4 шага)
📊 Эффективность метода
Длительность поиска методом половинного деления растёт как log₂(N).
| Размер данных (N) | Последовательный перебор (среднее) | Бинарный поиск (максимум) |
|---|---|---|
| 1 000 | 500 | 10 |
| 1 000 000 | 500 000 | 20 |
Разница кажется небольшой на малых данных, но когда данных миллионы (как в базах данных или индексах поисковиков), бинарный поиск работает в тысячи раз быстрее!
🌍 Где применяется в реальной жизни?
- Поиск в словарях и телефонных справочниках
- Индексы баз данных
- Поиск в Git истории коммитов
- Поиск в отсортированных массивах в программировании
- Системы навигации и карт
📌 Ключевые выводы
Подведём итоги изученного материала:
🤔 Проверь себя
Мини-кейсы и задачи для проверки понимания материала.
1. Мини-кейс про стриминг
Когда стример на Twitch транслирует игру, его компьютер сжимает видео, кодирует его, передаёт на сервер, который распределяет по зрителям, где видео декодируется и отображается.
Задание: Определи, какие типы обработки информации происходят на каждом этапе и какие исполнители участвуют.
2. Задача на комбинаторику
Система капчи использует 5 позиций, в каждой может быть одна из 10 цифр ИЛИ одна из 26 латинских букв.
Вопросы:
- Сколько различных капч можно создать?
- Почему это важно для безопасности?
3. Условие Фано в реальности
В URL-адресах используются символы и их процентное кодирование (например, пробел = %20).
Вопросы:
- Можно ли сказать, что эта система кодирования удовлетворяет условию Фано?
- Объясни, как браузер однозначно декодирует адреса.
4. Эксперимент с поиском
У тебя есть отсортированный список из 1024 элементов.
Вопросы:
- Сколько максимум сравнений потребует бинарный поиск?
- Почему именно столько? (Подсказка: связь с двоичными степенями)
5. Создай аналогию
Задание: Придумай метафору из повседневной жизни для объяснения разницы между последовательным и бинарным поиском.
Можешь использовать примеры из игр, соцсетей или любой другой области, знакомой тебе и твоим сверстникам.
6. Критическое мышление
Всегда ли бинарный поиск эффективнее последовательного?
Ситуация: Представь, что в небольшом неотсортированном списке ты знаешь, что нужный элемент, скорее всего, в начале.
Вопрос: Что выгоднее — сначала отсортировать и применить бинарный поиск или сразу искать последовательно?
📝 Вопросы и задания из учебника
Закрепляем теорию практикой.
Вопрос 1: Процессы обработки информации в жизни
Приведите примеры процессов обработки информации, которые чаще всего вам приходится выполнять в жизни.
Для каждого примера определите:
- Исходные данные
- Алгоритм (правила) обработки
- Получаемые результаты
- К какому типу обработки информации это относится?
Вопрос 2: Кодирование
Поясните суть понятий:
- Кодирование
- Код
- Кодовая таблица
Задача 3: Светодиодная панель
Светодиодная панель содержит шесть излучающих элементов, каждый из которых может светиться или красным, или жёлтым, или зелёным цветом.
Вопрос: Сколько различных сигналов можно передать с помощью панели (все излучающие элементы должны гореть, порядок цветов имеет значение)?
Задача 4: Автомобильные номера
Автомобильный номер состоит из нескольких букв (количество букв одинаковое во всех номерах), за которыми следуют три цифры. При этом используются 10 цифр и только 5 букв: A, B, C, D и F.
Вопрос: Требуется не менее 100 тысяч различных номеров. Какое наименьшее количество букв должно быть в автомобильном номере?
Задача 5: Последовательности с буквой А
Сколько существует различных последовательностей из 6 символов четырёхбуквенного алфавита {A, B, C, D}, которые содержат не менее двух букв А (т. е. две и более буквы А)?
Вопрос 6: Равномерные и неравномерные коды
Сравните равномерные и неравномерные коды.
Вопросы:
- Каковы их основные достоинства?
- Каковы их основные недостатки?
Вопрос 7: Префиксные коды
Вопросы:
- Какие коды называют префиксными?
- Почему они так важны?
- В чём суть прямого и обратного условий Фано?
Задача 8: Декодирование сообщений
Двоичные коды для 5 букв латинского алфавита представлены в таблице:
| A | B | C | D | E |
|---|---|---|---|---|
| 000 | 01 | 10 | 11 | 001 |
Из четырёх сообщений, закодированных этими кодами, только одно пришло без ошибки. Найдите его:
- 110100000100110011
- 111010000010010011
- 110100001001100111
- 110110000100110010
Задача 9: Кодирование буквы Д
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность.
При этом используются следующие коды: А — 1110, Б — 0, В — 10, Г — 110.
Вопрос: Каким кодовым словом может быть закодирована буква Д? Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
Задача 10: Троичный код
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, используется неравномерный троичный код, позволяющий однозначно декодировать полученную троичную последовательность.
Вот этот код: А — 0, Б — 11, В — 20, Г — 21, Д — 22.
Вопрос: Можно ли сократить для одной из букв длину кодового слова так, чтобы закодированную последовательность по-прежнему можно было декодировать однозначно? Коды остальных букв меняться не должны.
Задача 11: Кодовые слова без трёх одинаковых букв подряд
Для передачи закодированных сообщений используется таблица кодовых слов из четырёх букв. Причем используются только буквы А, Р и У.
Вопрос: Сколько различных кодовых слов может быть в такой таблице, если ни в одном слове нет трёх одинаковых букв, идущих подряд?
Задача 12: Поиск методом половинного деления
Методом половинного деления в последовательности чисел
061 087 154 180 208 230 290 345 367 389 456 478 523 567 590 612требуется найти число 590.
Задание: Опишите процесс поиска.
Задача 13: Склад плотника (конкурс "Бобёр")
Плотник в Бобровой Деревне использует 31 склад, пронумерованный от 1 до 31. Однажды он забыл, сколько складов уже заполнил, но помнит, что заполнял их в порядке возрастания номеров.
Его стратегия:
- Сначала открывает склад со средним номером — склад № 16
- Если склад № 16 пуст, он ищет в промежутке от № 1 до № 15, открывает средний склад № 8 и повторяет процедуру
- Если склад № 16 заполнен, то ищет между № 17 и № 31, открывает средний склад № 24 и повторяет процедуру
После всех действий плотник обнаружил, что заполнены были склады от № 1 до № 15 включительно.
Вопросы:
- Сколько дверей ему пришлось открыть?
- Какой из рассмотренных методов поиска был использован героем этой задачи?